1.1.2🔍 Detección y Análisis
🔍 Detection & Analysis – Parte 1
En esta fase comienza la acción real: detectar y comprender incidentes para responder adecuadamente.
🧭 ¿Qué incluye esta etapa?
-
Uso de sensores, registros (logs) y personal capacitado
-
Compartición de información y conocimiento
-
Aplicación de inteligencia de amenazas contextual
-
Segmentación de red y visibilidad total de la arquitectura
🛠️ Fuentes comunes de detección
-
Un empleado nota comportamiento anómalo
-
Alertas de herramientas: EDR, IDS, firewall, SIEM...
-
Actividades de threat hunting
-
Notificación externa (proveedor, CERT, etc.)
-
EDR (Endpoint Detection and Response):
Detecta y responde a actividades maliciosas directamente en los endpoints (estaciones de trabajo, servidores, etc.). Si se detecta un software malicioso o u1n comportamiento extraño, el EDR emite alertas. -
IDS (Intrusion Detection System):
Monitorea el tráfico de red y genera alertas cuando se detectan patrones que coinciden con firmas conocidas de ataques o comportamientos anómalos. -
Firewall:
Controla y filtra el tráfico entrante y saliente de la red. Si detecta paquetes no autorizados, intentos de escaneo o conexiones de IPs sospechosas, puede generar alertas. -
SIEM (Security Information and Event Management):
Recoge y analiza grandes cantidades de logs provenientes de diferentes fuentes (servidores, aplicaciones, redes). Detecta correlaciones entre eventos y puede emitir alertas sobre incidentes de seguridad basados en comportamientos anómalos o en la ocurrencia de eventos de alto riesgo. -
Threat hunting o "caza de amenazas":
Actividad proactiva en la que los analistas de seguridad buscan de manera activa signos de intrusiones o actividades maliciosas dentro de la red y los sistemas, en lugar de esperar a que los eventos sean detectados por herramientas automáticas. -
CERT (Computer Emergency Response Team):
Un CERT emite un boletín de seguridad sobre una nueva vulnerabilidad que afecta a ciertos sistemas o aplicaciones utilizados por la organización, proporcionando alertas externas sobre posibles riesgos.
🧱 Niveles de detección recomendados
Organizar detección por capas lógicas de red:
| Nivel | Ejemplos de herramientas/acciones |
|---|---|
| 🔰 Perímetro de red | Firewalls, IDS/IPS perimetral, DMZ |
| 🏢 Red interna | Firewalls locales, HIDS/HIPS |
| 💻 Endpoints | Antivirus, EDR |
| 🧩 Aplicaciones | Logs de servicios, apps y sistemas |
🔎 Investigación inicial
Antes de lanzar una respuesta a gran escala, realiza una evaluación rápida:
Recoge información como:
-
Fecha/hora y quién reportó/detectó el incidente
-
Cómo fue detectado
-
Tipo de incidente (phishing, malware, caída de servicios, etc.)
-
Sistemas afectados
-
Quién accedió a los sistemas afectados y qué hizo
-
Estado actual: ¿incidente activo o contenido?
-
Detalles técnicos: IPs, sistemas operativos, dueño del sistema, finalidad, ubicación física
-
(Si aplica malware): tipo, hash, dispositivos afectados, archivos maliciosos extraídos
⚠️ El contexto es clave. No es igual un incidente en el portátil del CEO que en el de un becario.
📆 Construcción de la línea de tiempo del incidente
Objetivo: entender qué pasó, cuándo, y cómo.
| Fecha | Hora | Hostname | Descripción del evento | Fuente del dato |
|---|---|---|---|---|
| 09/09/2021 | 13:31 CET | SQLServer01 | Herramienta Mimikatz detectada | Software antivirus |
-
La línea de tiempo reordena eventos cronológicamente, incluso si fueron descubiertos fuera de orden
-
Ayuda a distinguir entre actividad relacionada y no relacionada
🧮 Preguntas clave para medir severidad y alcance
-
¿Cuál es el impacto de la explotación?
-
¿Qué requiere el exploit para ejecutarse?
-
¿Puede afectar sistemas críticos?
-
¿Hay pasos de remediación disponibles?
-
¿Cuántos sistemas están afectados?
-
¿El exploit está siendo usado activamente en la red o en internet?
-
¿Tiene capacidades tipo "gusano"?
❗ Exploits activos y con propagación automática sugieren un adversario avanzado.
🔐 Confidencialidad y comunicación
-
Toda la información debe ser manejada con estricto control
-
Solo personas con necesidad de saber deben tener acceso
-
Las comunicaciones internas/externas deben ser dirigidas por el responsable designado junto al equipo legal
Expectativas al iniciar la investigación
-
Tipo de incidente
-
Fuentes de evidencia disponibles
-
Tiempo estimado de investigación
-
Posibilidad de identificar al atacante
⚠️ Todo esto puede cambiar a medida que se descubren nuevas pistas. La clave es mantener a todos informados y al tanto del progreso.
🔍 Etapa de Detección y Análisis – Parte 2
🚀 ¿Por qué es importante entender cómo ocurrió un incidente?
-
Sin un análisis exhaustivo, las medidas correctivas podrían no prevenir futuros accesos.
-
Conocer el vector de ataque, las herramientas utilizadas y los sistemas afectados nos permite cerrar esas brechas y evitar que el atacante retome el control.
🔄 Proceso de Investigación Cíclica
La investigación se desarrolla en un ciclo continuo que involucra:
-
Creación y uso de IOC (Indicadores de Compromiso)
-
Identificación de nuevos sistemas afectados o clientes potenciales
-
Recopilación y análisis de datos de estos nuevos sistemas
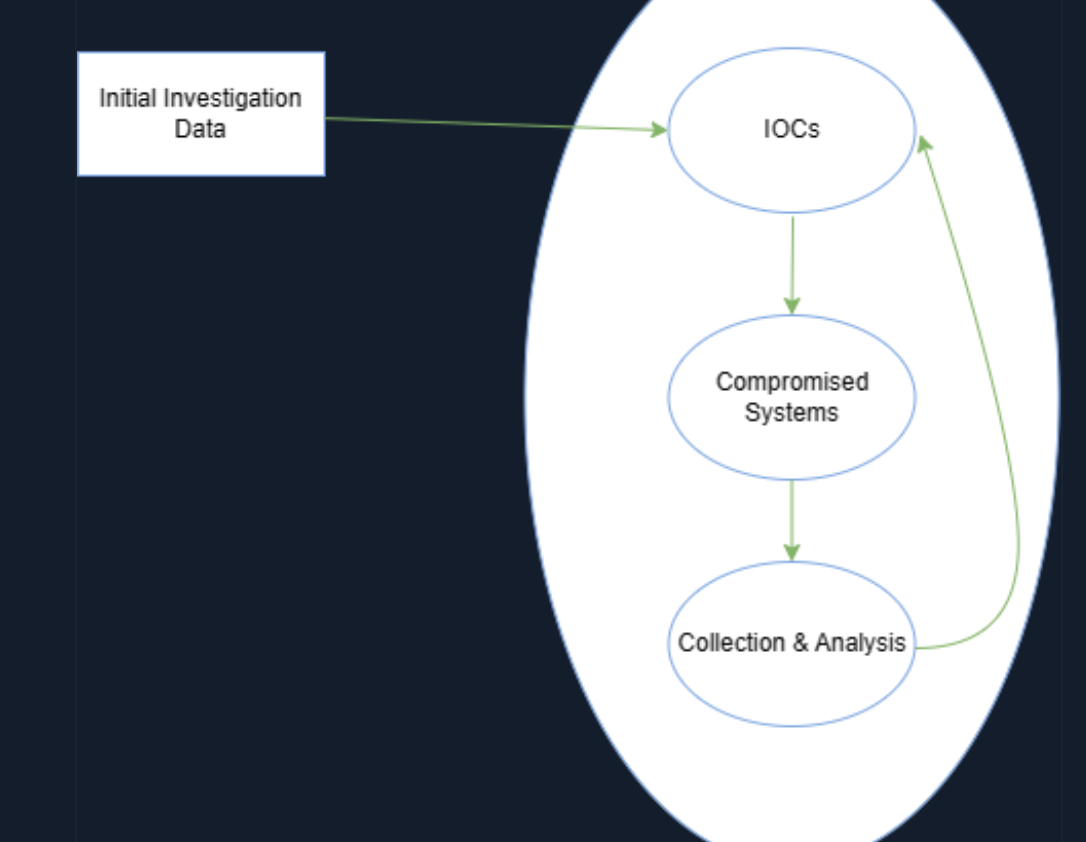
🧠 Datos de la Investigación Inicial
-
La investigación comienza con los datos limitados obtenidos en una fase temprana. No debemos centrarnos solo en una pista (como una herramienta maliciosa conocida).
-
La clave está en identificar constantemente nuevas pistas a lo largo del proceso.
🛠️ Creación y Uso de IOC
Los Indicadores de Compromiso (IOC) son pruebas o artefactos que indican que ha ocurrido un incidente. Los IOC se documentan de forma estructurada y pueden incluir:
-
Direcciones IP
-
Hashes de archivos
-
Nombres de archivos
-
Herramientas como OpenIOC o Yara permiten compartir y documentar estos artefactos de forma estándar.
Uso de herramientas:
-
Herramientas para obtener y buscar IOC (por ejemplo, WMI, PowerShell en Windows).
-
Precaución con las credenciales: Evitar que las credenciales de usuarios con privilegios elevados queden almacenadas en caché al conectarse a sistemas comprometidos. Ejemplo: PsExec almacena credenciales si se proporcionan explícitamente, pero no lo hace si no se indican.
🔍 Identificación de Nuevos Clientes y Sistemas Afectados
-
Búsqueda de coincidencias: Una vez que tenemos los IOC, buscamos otras posibles coincidencias en los sistemas. Estas coincidencias pueden revelar sistemas adicionales afectados, pero hay que eliminar falsos positivos.
-
Priorización: En caso de encontrar muchas coincidencias, priorizamos aquellas que puedan ofrecernos más pistas relevantes.
📝 Recopilación y Análisis de Datos
Recopilación de Datos
Cuando identificamos sistemas afectados, debemos preservar su estado para su análisis posterior. El enfoque de respuesta en vivo es el más común:
-
Respuesta en vivo: Recopilamos datos sin apagar el sistema, lo que nos permite obtener artefactos valiosos que se encuentran en la memoria RAM.
-
Apagar el sistema: En algunos casos, apagar un sistema puede eliminar artefactos críticos de la memoria, por lo que este enfoque debe ser manejado con cuidado.
Consideración clave: Sea cual sea el enfoque, es importante evitar alterar evidencia o artefactos en los sistemas.
Análisis de Datos
-
Análisis de malware: Detectar y analizar software malicioso encontrado en el sistema afectado.
-
Análisis forense de discos: Revisar discos duros en busca de artefactos y evidencias de la intrusión.
-
Análisis de memoria: Cada vez más relevante, especialmente cuando se trata de ataques avanzados.
🏛️ Cadena de Custodia
Durante el proceso de recopilación de datos, debemos registrar la cadena de custodia de los artefactos para asegurar que toda la evidencia sea admisible ante los tribunales si se procede legalmente contra el adversario.
🔄 Actualización de la Línea de Tiempo
A medida que descubrimos nuevas pistas y validamos datos, actualizamos constantemente la línea de tiempo del incidente para mantener un registro claro de los eventos ocurridos.
⚠️ Precauciones y Consideraciones
-
Credenciales almacenadas: Asegurarse de que las credenciales de usuario no se almacenen en caché accidentalmente durante la investigación.
-
Eliminación de falsos positivos: Necesitamos eliminar rápidamente coincidencias que no sean relevantes, para centrarnos en las pistas que realmente aporten información valiosa.
-
Minimización del impacto: Cualquier acción que realicemos sobre los sistemas afectados debe estar orientada a no alterar ni eliminar evidencia valiosa.
🧩 Resumen de Pasos
-
Iniciar con los datos iniciales obtenidos al principio de la investigación.
-
Usar IOC para identificar artefactos y compartirlos.
-
Identificar nuevos sistemas comprometidos a través de la búsqueda de IOC.
-
Recopilar y analizar datos de sistemas comprometidos para obtener más pistas.
-
Mantener actualizada la línea de tiempo del incidente y registrar la cadena de custodia.