🕷️ Web Crawling — Rastreando Sitios Web
Técnica automatizada para navegar sitios web y recolectar información útil para análisis, reconocimiento o indexación.
🚀 ¿Qué es el Crawling?
Similar a una araña en su telaraña, un crawler sigue enlaces entre páginas, recolectando información automáticamente.
🧠 También conocido como spidering, este proceso es clave para:
-
🔍 Indexación por buscadores
-
🧪 Reconocimiento en pentesting
-
📊 Extracción de datos (scraping)
⚙️ ¿Cómo funciona un Web Crawler?
-
🌱 Seed URL (página inicial)
-
🔗 Extrae enlaces (internos y externos)
-
📥 Añade esos enlaces a una cola
-
🔁 Repite el proceso recursivamente
Homepage
├── link1
├── link2
└── link3
link1 Page
├── Homepage
├── link2
├── link4
└── link5
➡️ Así se explora sistemáticamente todo un sitio web.
🔁 Estrategias de Crawling
🌐 Breadth-First (anchura primero)
-
Primero explora todas las páginas del mismo nivel
-
Luego pasa al siguiente nivel de enlaces
-
🔍 Ideal para mapear estructura general
📈 Ejemplo:
Inicio → link1, link2 → link1.1, link2.1
📚 Depth-First (profundidad primero)
-
Sigue una rama completa hasta el fondo
-
Luego retrocede y sigue otra
-
🎯 Útil para contenido profundo o escondido
📈 Ejemplo:
Inicio → link1 → link1.1 → link1.1.1
💎 Información valiosa que puede extraerse
| Tipo | Descripción | Utilidad |
|---|---|---|
| 🔗 Links | Internos y externos | Mapear la web, detectar secciones ocultas |
| 💬 Comentarios | Foros, blogs, etc. | Puede revelar info sensible |
| 📇 Metadata | Títulos, autores, fechas | Contexto del sitio |
| 🧾 Archivos sensibles | .bak, config.php, logs | Pueden contener credenciales, claves, etc. |
⚠️ Un solo dato puede parecer trivial, pero al conectarlo con otros, puede revelar una vulnerabilidad crítica.
📜 El archivo robots.txt
📌 Similar a un letrero "Privado" en una casa:
User-agent: *
Disallow: /private/
🔎 Define qué pueden y qué no deben visitar los crawlers.
| Directiva | Descripción | Ejemplo |
|---|---|---|
| Disallow | Bloquea acceso a rutas | Disallow: /admin/ |
| Allow | Permite rutas específicas | Allow: /public/ |
| Crawl-delay | Retrasa peticiones | Crawl-delay: 10 |
| Sitemap | Apunta a sitemap XML | Sitemap: https://example.com/sitemap.xml |
✅ Respetado por crawlers legítimos, pero no obligatorio.
🧰 Herramientas de Crawling
🕸️ Burp Suite Spider
-
Integra spidering con testing manual y automático
-
🔎 Mapea apps web, detecta rutas ocultas
-
💥 Complementa otras fases de pentesting
🕵️ OWASP ZAP Spider
-
🔓 Herramienta libre y open-source
-
Rastreo + escaneo de seguridad
-
🧪 Ideal para pruebas automatizadas
🐍 Scrapy (Python)
-
Framework poderoso para scraping + crawling
-
Escalable y flexible
-
🎯 Ideal para crawlers personalizados
pip3 install scrapy
🧱 Apache Nutch
-
Potente crawler en Java
-
Para proyectos a gran escala
-
🧠 Necesita configuración técnica avanzada
🐍 Scrapy + ReconSpider en HTB
🧬 Usamos una araña personalizada ReconSpider para inlanefreight.com:
- 📦 Instalar Scrapy:
pip3 install scrapy
- ⬇️ Descargar y extraer la araña:
wget -O ReconSpider.zip https://academy.hackthebox.com/storage/modules/144/ReconSpider.v1.2.zip
unzip ReconSpider.zip
- 🚀 Ejecutar:
python3 ReconSpider.py http://inlanefreight.com
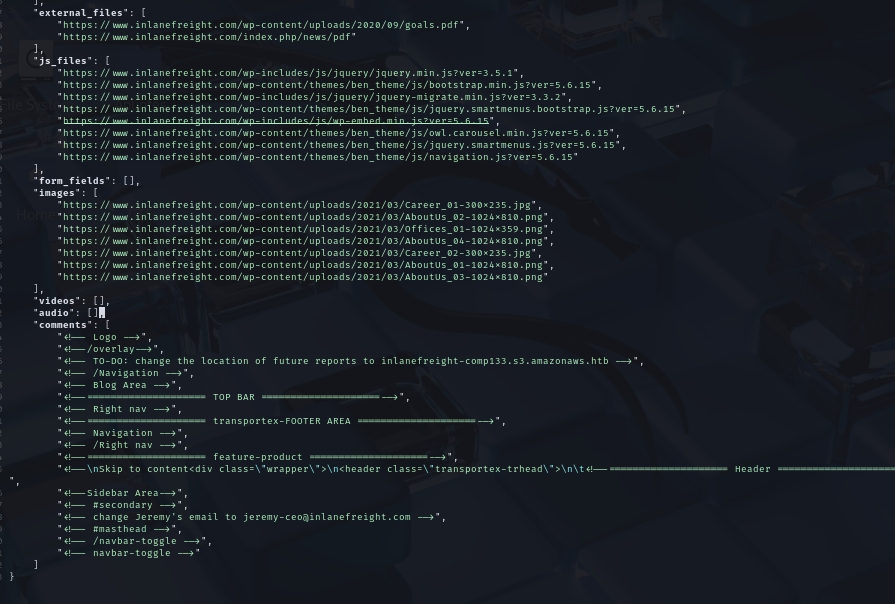
📌 Sustituye el dominio por tu objetivo.
🧠 Este script rastrea y recolecta páginas, metadatos, archivos y más.
🧩 Comparativa: Crawling vs Fuzzing
| Aspecto | Crawling | Fuzzing |
|---|---|---|
| 🔍 Método | Sigue enlaces existentes | Genera rutas y prueba |
| ⚙️ Base | Datos reales del sitio | Fuerza bruta (diccionarios) |
| 🎯 Objetivo | Explorar contenido expuesto | Descubrir contenido oculto |
| 🔒 Precisión | Alta (menos falsos positivos) | Media-baja (requiere verificación) |
📚 Conclusión
-
Crawling es clave para el reconocimiento inicial
-
Permite mapear el sitio, encontrar archivos expuestos, metadatos y más
-
Combinado con análisis contextual, puede llevarte a hallazgos críticos 🎯